 Welcome
Welcome
View updates to recent projects and other technical notes:
Large Language Model Accelerator using Process-in-Memory and Network-on-Chip
Project Objective
This project aims to build a small-scale prototype of a LLM accelerator, particularly focusing on inference of self-headed attention using PIM-NoC designs. Based on the findings from designing this small-scale PIM-NoC accelerator, the plan is to design a LLM accelerator on a FPGA that can be marketable for edge-computing in industrial settings.
Background
Given the prevalence of GPUs used for Large language model (LLM) inference and its inherent energy loss due to movements of data between memory and logic, Process-in-Memory (PIM) architectures combined with Network on Chip (NoC) protocols have arose as a viable option to reduce energy usage while satisfying latency and throughput requirements, especially for edge-computing. In PIM, computational tasks are performed in memory itself removing the physical separation of memory and logic. NoC protocols complement PIM by transferring the required information between PIM nodes to efficiently build circuits that perform complex logic functions. PIM-NoC accelerators can also map LLM layers onto different sections of the memory array, allowing hardware to take advantage of the parallel computing algrithms.
Design Overview
Hardware block diagrams are provided in figures 1 and 2:
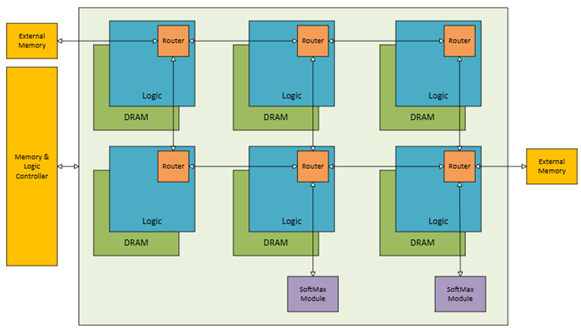
Figure 1: High level hardware block diagram
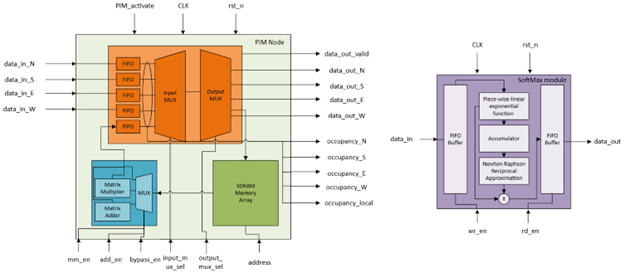
Figure 2: Low level hardware block diagram
- Memory Technology: DRAM was selected for cost and simplicityof simulation. Each DRAM memory cell can hold 32 rows of 32bit data (128Bytes).
Decision factor: Studies have explored improving PIM designs with other common memory types like NAND flash, SRAM, 3-D stacked DRAM variants (HBM or HMC). Recent research has shifted toward emerging technologies such as metal-oxide resistive RAM (ReRAM) which performs matrix calculations directly on the memory array, resulting in improve latency than DRAM. There is a trade-off between cost (fabrication yield) and latency.
- Precision & Quantization: weights were stored as 32bit fixed point values (Q16.16).
Decision factor: Quantization is commonly used to approximate the weights at lower bit-precision such as 16-bit floating point, 8-bit fixed point, even down to 1-bit quantization. There is a trade-off between latency and accuracy of the model though studies have shown that models can achieve negligible accuracy loss when weights are trained using 8-bit floating point values. For a small-scall simulation like this, memory size is not a constraint.
- Routing Protocol: Dataflow is managed at each node by instruction sets defined in the memory & logic controller which is based on the X-Y routing protocol.
Decision factor: NoC routing protocol can be classified as either either deterministic or dynamic. Deterministic (such as X-Y protocol) is simple to implement and deadlock free. Whereas, dynamic protocols (such as distance vector routing protocol) are complex to implement but has low latency. There is a trade-off between latency and design complexity. To simplify design, X-Y protocol was chosen.
- Router design: Routers used in this simulation were based on a baseline design commonly used in research with a FIFO (First-in First-out) buffer, crossbar switch, and an arbiter to choose the packets forwarded to the selected output ports.
Decision factor: Given the use of a external controller sending instructions sets to each router using the X-Y protocol, the router design did not require packet decoders and communication lines with adjacent nodes.
- Number of PIM nodes: Six PIM nodes were connected in a 2D-mesh orientation.
Decision factor: This design was used to simplify the Weight-satationary dataflow and to reduce the number of hops required to transmit data. The dataflow is illustrated in figures 3 and 4. This is a trade-off with latency as a larger number of nodes require smaller memory at each node, resulting in faster MM&A operations using smaller matrices.
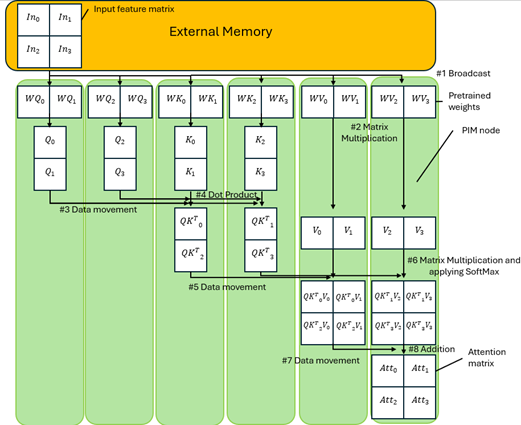
Figure 3: Illustrated dataflow of weight-stationary method of inference
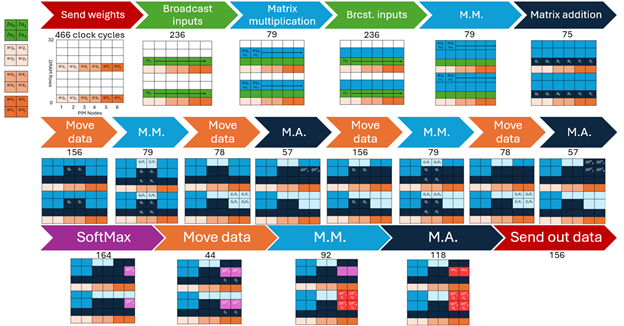
Figure 4: Tiling used to move data between the PIM nodes based on weight-stationary dataflow
Demonstration
Hardware simulation based on the above design was coded in systemVerilog.One self-headed attention calculation using the PIM-NoC required 296 router hops and 224 internal DRAM data movements where one hope and one movement consist of moving 32 bits. The table below shows the latency and expected energy efficiency based on electrical interconnects using 3pJ/bit and DRAM internal memory movements using 0.88pJ/bit. The benchmark was provided running a PyTorch script using the same input and weights, measuring the time required to complete the calculation. The benchmark estimates 5us of CPU runtime as the data size was too small to obtain an accurate measure of CPU clock cycles.
| Criteria | PIM-NoC | CPU |
|---|---|---|
| Energy (uJ) | 35 | 75 |
| Latency (clock cycle) | 3,170 | 25,000 |
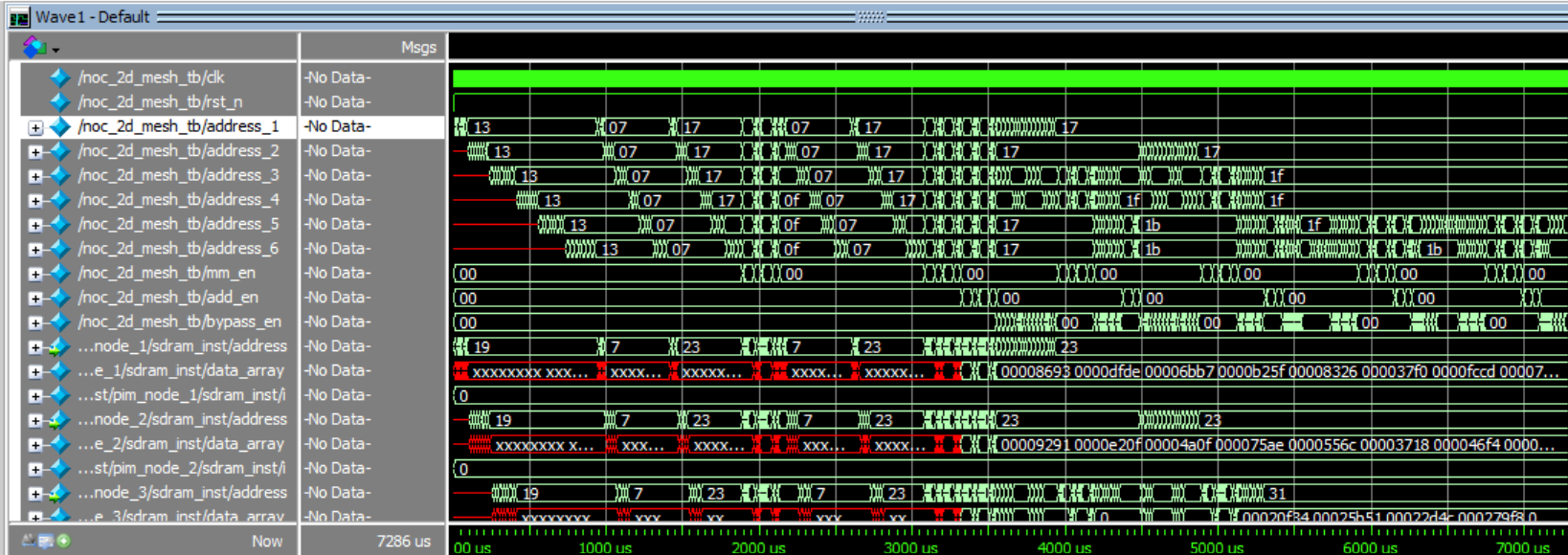
Figure 5: RTL simulation results used to compute total clock cycles and energy consumption
Improvements for Full-Scale Design
Three design improvements to reduce latency and improve energy efficiency were identified:
-
Increasing the number of connections between the PIM nodes with the external buffer would impact latency as it will affect input broadcasting which consisted 31% of total clock cycles.
-
Increassing the number of nodes performing MM&A before sending data to the SoftMax module affects latency as dataflow can be designed to perform recursive operations parallelly using more nodes.
-
Using FlashAttention to apply SoftMax functions or other non-linear functions within the node. This removes the need for an external buffer which further reduces latency and memory requirements.
References
-
Zhou, M., Chen, G., Imani, M., Gupta, S., Zhang W., and Rosing, T. (2021) PIM-DL: Boosting DNN Inference on Digital Processing In-Memory Architectures via Data Layout Optimizations. 2021 30th International Conference on Parallel Architectures and Compilation Techniques (PACT), Atlanta, GA, USA, 2021, pp. 1-1.
-
Sebastian, A., Le Gallo, M., Khaddam-Aljameh, R., and Eleftheriou, E. (2020). “Memory devices and applications for in-memory computing,” Nature nanotechnology, vol. 15, no. 7, pp. 529–544.
-
Chen, Y. H., Emer, J., and Sze, V. (2017). Using Dataflow to Optimize Energy Efficiency of Deep Neural Network Accelerators. IEEE Micro, vol. 37, no. 3, pp. 12-21, 2017.
-
Asifuzzaman, K., Miniskar, N.R., Young, A. R., Liu, F., Vetter, J. S. (2023).A survey on processing-in-memory techniques: Advances and challenges,Memories - Materials, Devices, Circuits and Systems,Volume 4, 2023,100022, ISSN 2773-0646.
-
Belmonte, A., Oh, H., Rassoul, N., Donadio, G. L., Mitard, J., Dekkers., H. (2020). Capacitor-less, Long-Retention (>400s) DRAM Cell Paving the Way towards Low-Power and High-Density Monolithic 3D DRAM, 2020 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 2020, pp. 28.2.1-28.2.4.
Acknowledgements
I would like to thank Dr. Kelvin Fong Xuanyao, and members of the SEEDER Group at the National University of Singapore for mentorship throughout this project. Specifically, Yimin Wang on guidance on project scope, Yue Jiet Chong for training on NoC designs, and Wu Zhen for advice on implementation of the SoftMax module.